 微信客服
微信客服華爾街深度研究:DeepSeek是AI末日嗎?
來源:華爾街見聞
春節期間,DeepSeek新一代開源模型以驚人的低成本和高性能引發熱議,在全球投資界引發劇震。
市場上甚至出現了DeepSeek“僅用500萬美元就複製OpenAI”的說法,認為這將給整個AI基礎設施產業帶來“末日”。
對此,華爾街知名投行伯恩斯坦在詳細研究DeepSeek技術文檔後發布報告稱,這種市場恐慌情緒明顯過度,DeepSeek用“500萬美元複製OpenAI”是市場誤讀。
另外,該行認為,雖然DeepSeek的效率提升顯著,但從技術角度看,並非奇跡。而且,即便DeepSeek確實實現了10倍的效率提升,這也僅相當於當前AI模型每年的成本增長幅度。
該行還表示,目前AI計算需求遠未觸及天花板,新增算力很可能會被不斷增長的使用需求吸收,因此對AI板塊保持樂觀。
“500萬美元複製OpenAI”是誤讀
對於“500萬美元複製OpenAI”的說法,伯恩斯坦認為,實際上是對DeepSeek V3模型訓練成本的片麵解讀,簡單將GPU租用成本計算等同於了總投入:
這500萬美元僅僅是基於每GPU小時2美元的租賃價格估算的V3模型訓練成本,並未包括前期研發投入、數據成本以及其他相關費用。
技術創新:效率大幅提升但非顛覆性突破
接著,伯恩斯坦在報告中詳細分析了DeepSeek發布的兩大模型V3、R1詳細技術特點。
(1)V3模型的效率革命
該行表示,V3模型采用專家混合架構,用2048塊NVIDIA H800 GPU、約270萬GPU小時就達到了可與主流大模型媲美的性能。
具體而言,V3模型采用了混合專家(MoE)架構,這一架構本身就旨在降低訓練和運行成本。在此基礎上,V3還結合了多頭潛在注意力(MHLA)技術,顯著降低了緩存大小和內存使用。
同時,FP8混合精度訓練的運用進一步優化了性能表現。這些技術的綜合運用,使得V3模型在訓練時僅需同等規模開源模型約9%的算力,便能達到甚至超越其性能。
例如,V3預訓練僅需約270萬GPU小時,而同樣規模的開源LLaMA模型則需要約3000萬GPU小時。
MoE架構: 每次隻激活部分參數,減少計算量。MHLA技術: 降低內存占用,提升效率。FP8混合精度訓練: 在保證性能的同時,進一步提升計算效率。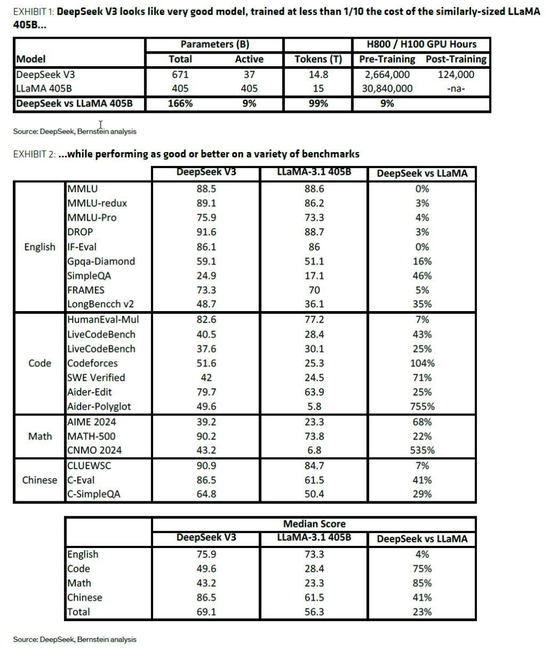
談及V3模型帶來的效率提升,伯恩斯坦認為,與業界3-7倍的常見效率提升相比並非顛覆性突破:
MoE架構的重點是顯著降低訓練和運行的成本,因為在任何一次隻有一部分參數集是活動的(例如,當訓練V3時,隻有671B個參數中的37B為任何一個令牌更新,而密集模型中所有參數都被更新)。
對其他MoE比較的調查表明,典型的效率是3-7倍,而類似大小的密度模型具有類似的性能;
V3看起來甚至比這個更好(10倍以上),可能考慮到該公司在模型中帶來的其他一些創新,但認為這是完全革命性的想法似乎有點誇張,並且不值得在過去幾天裏席卷twitter世界的歇斯底裏。
(2)R1模型的推理能力與“蒸餾”策略
DeepSeek的R1模型則在V3的基礎上,通過強化學習(RL)等創新技術,顯著提升了推理能力,使其能夠與OpenAI的o1模型相媲美。
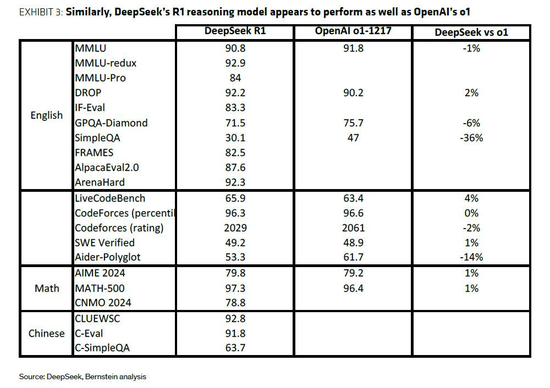
值得一提的是,DeepSeek還采用了“模型蒸餾”策略,利用R1模型作為“教師”,生成數據來微調更小的模型,這些小模型在性能上可以與OpenAI的o1-mini等競爭模型相媲美。這種策略不僅降低了成本,也為AI技術的普及提供了新的思路。
強化學習(RL): 提升模型推理能力。模型蒸餾: 利用大模型訓練小模型,降低成本。對AI板塊保持樂觀
伯恩斯坦認為,即便DeepSeek確實實現了10倍的效率提升,這也僅相當於當前AI模型每年的成本增長幅度。
事實上,在“模型規模定律”不斷推動成本上升的背景下,像MoE、模型蒸餾、混合精度計算等創新對AI發展至關重要。
根據傑文斯悖論,效率提升通常會帶來更大的需求,而非削減開支。該行認為,目前AI計算需求遠未觸及天花板,新增算力很可能會被不斷增長的使用需求吸收。
基於以上分析,伯恩斯坦對AI板塊保持樂觀。
如果您对本站有任何建议,欢迎您提出来!本站部分信息来源于网络,如果侵犯了您权益,请联系我们删除!



